Everything you need to know about S3

Seasoned technologist with 8 years of experience, successfully delivering projects and managing teams. Passionate about leveraging cutting-edge technology to solve complex business challenges across various domains. Proven track record of driving innovation, efficiency, and growth through tailored technological solutions.
This article covers the essential S3 features that every developer should be familiar with before working with AWS S3.
As a developer, we are often in a situation, where we need to build a solution that end users upload documents to the server. Sometimes files may be of different sizes and users who are uploading the files may be from different parts of the world, users who are far away from our server may face a poor user experience in uploading the file.

How can we overcome these kinds of issues, when we think of uploading files to the server?
AWS S3 comes to our rescue, one of the storage solutions from Amazon Web Service.
What is AWS S3?
AWS offers 3 types of storage solutions, Block storage, File storage, and Object storage. AWS S3 (Simple Storage Service) is an object storage solution, which is highly durable, scalable and offers the best performance. S3 stores all its objects inside a bucket. S3 is a regional service, which means it is regionally resilient and any data uploaded to the S3 bucket will be replicated across 3 Availability zones, this may vary based on the storage class selected.
What is an S3 Object?
An object is a file and metadata that describes the file. Objects are stored as Key-Value pairs, Key uniquely identifies an object. Value stores the content of the object. Objects contain version ID, which is used when versioning is enabled in the bucket. An object also contains, a set of name-value pairs which describe the object, these are user-defined values.
What is an S3 Bucket?
Buckets are containers of objects. To store the data in the S3 we need to create the buckets. Considerations before creating the buckets
Bucket names should be globally unique, whenever you create a bucket it should be unique across all the AWS accounts.
The bucket name should be 3 - 63 characters long.
Every account has 100 as the soft limit and 1000 as the hard limit (Increased through an AWS support ticket).
Unlimited objects can be uploaded to a bucket, a object can vary from size 0 to 5 TB.
Bucket names can't be formatted like an IP address.
The S3 data model is a flat structure, it doesn't support hierarchy. Objects can have prefixes, which may appear to be a hierarchy in AWS Console. Delimiter (/) is used to split the prefixes. For Example, India/TamilNadu/Coimbatore.jpeg, where India/ and India/TamilNadu/ are prefixes, these prefixes help to organize the content.
Okay now you got the idea that S3 Buckets are useful to store only the objects, but wait, they can able to do more.

Apart from storing the files, buckets can be used to host static websites, this should be explicitly enabled in the bucket, there are a few considerations you need to be aware of when we plan to host the static website through AWS S3.
The bucket name should match the root domain or subdomain.
We should provide the index.html and error.html pages explicitly in the bucket configuration.
The website endpoint will be in HTTP, to enable HTTPS communication, you should configure with the Amazon CloudFront.
Object Versioning
Object versioning once enabled on the bucket, lets us store multiple versions of a single object. Object versioning is disabled by default, once enabled then it can only be suspended, it can't be disabled again, and the suspended versioning can be enabled again. It is important to remember that once versioning is enabled it cannot be disabled again.
Now you may be wondering what's the use of Object versioning, think of what Git solves with versions is what object versioning is doing for the objects.
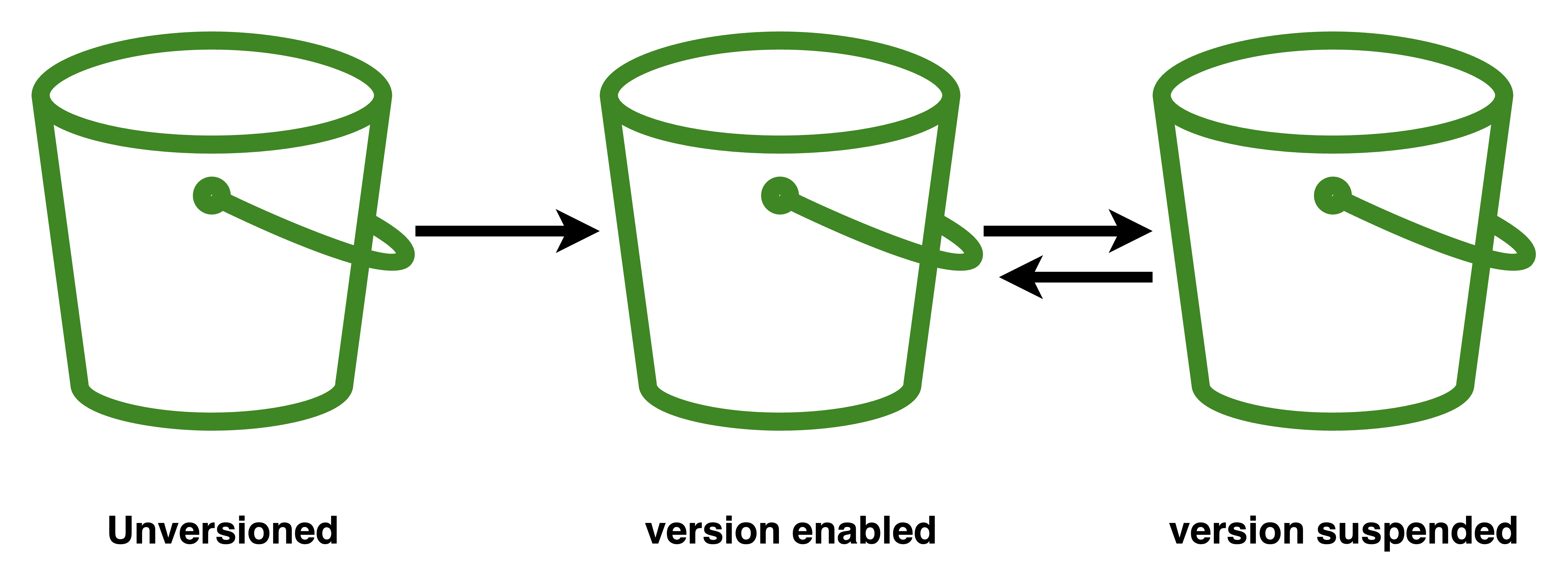
The cost will be calculated for objects including their versions. Versioning is maintained by Version ID, which is generated by AWS. When we delete an object in a bucket with versioning enabled, actually it is not deleted from the bucket, instead, a delete marker (a placeholder/marker for a versioned object) is added to that object, which makes S3 behave as if the object has been deleted. We can able to delete the specific version of the object by mentioning the Version ID during deletion.
When we delete the latest version of the object, the previous version becomes the latest version of the object. Each time an object is fetched only the latest version of the object is fetched. Some other features of the S3 bucket require object versioning to be enabled, bucket replication feature requires object versioning.
MFA Delete
MFA Delete is one of the S3 bucket features, which is enabled during object versioning. MFA Delete stands for Multi-Factor Authentication Delete, which provides additional security against the accidental deletion of objects. It requires security credentials with MFA serial number and MFA serial code along with the delete request. MFA deletion requires additional authentication, in the following scenario, when we are changing the versioning state of the bucket and permanently deleting the version of the object.

S3 Encryption
You may be wondering how the data are protected in AWS S3. Encryption is a must when we talk about data protection. S3 buckets are not encrypted, only the objects are encrypted. When we talk about encryption, the data should be encrypted during transit and at rest. S3 encryption is disabled by default. S3 objects are encrypted by default during transit (HTTPS) when it travels from the client side to the server side. S3 objects encrypted at rest are implemented in different ways,
Client Side Encryption
Server Side Encryption
Server-side encryption with customer-provided keys (SSE-C)
Server-side encryption with S3 managed keys (SSE-S3)
Server-side encryption with KMS (SSE-KMS)

Client-side encryption
Data are encrypted on the client side itself before they leave the client. It is compute-heavy on the client side. The encryption process and encryption keys are maintained at the client end.
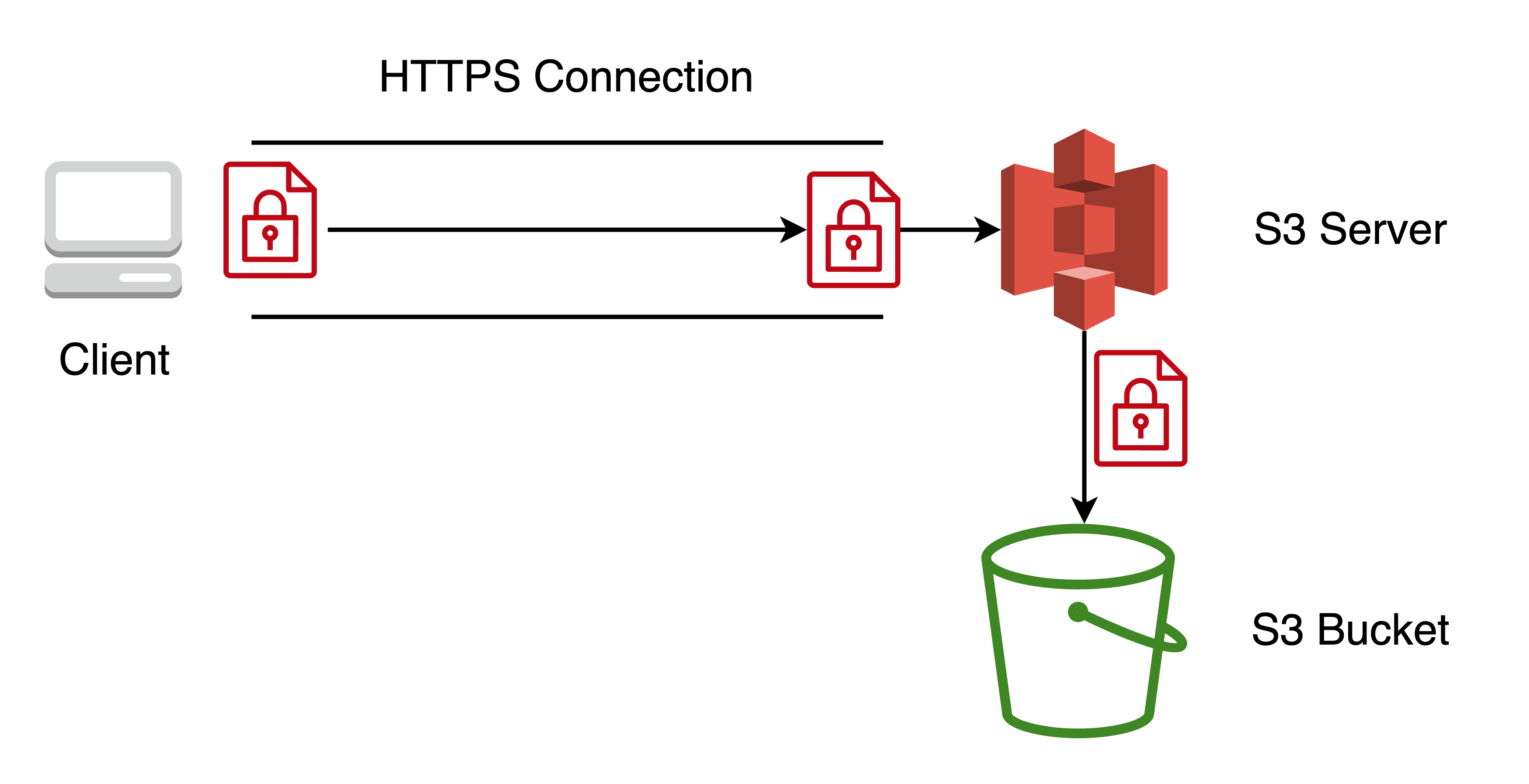
Server-side encryption with customer-provided keys (SSE-C)
While uploading the data to the S3, the client will send the keys to encrypt and decrypt along with the object. Here key management is done by the client side. The encryption and Decryption process is done on the server side. Server-side encryption encrypts the object data and not the object metadata.
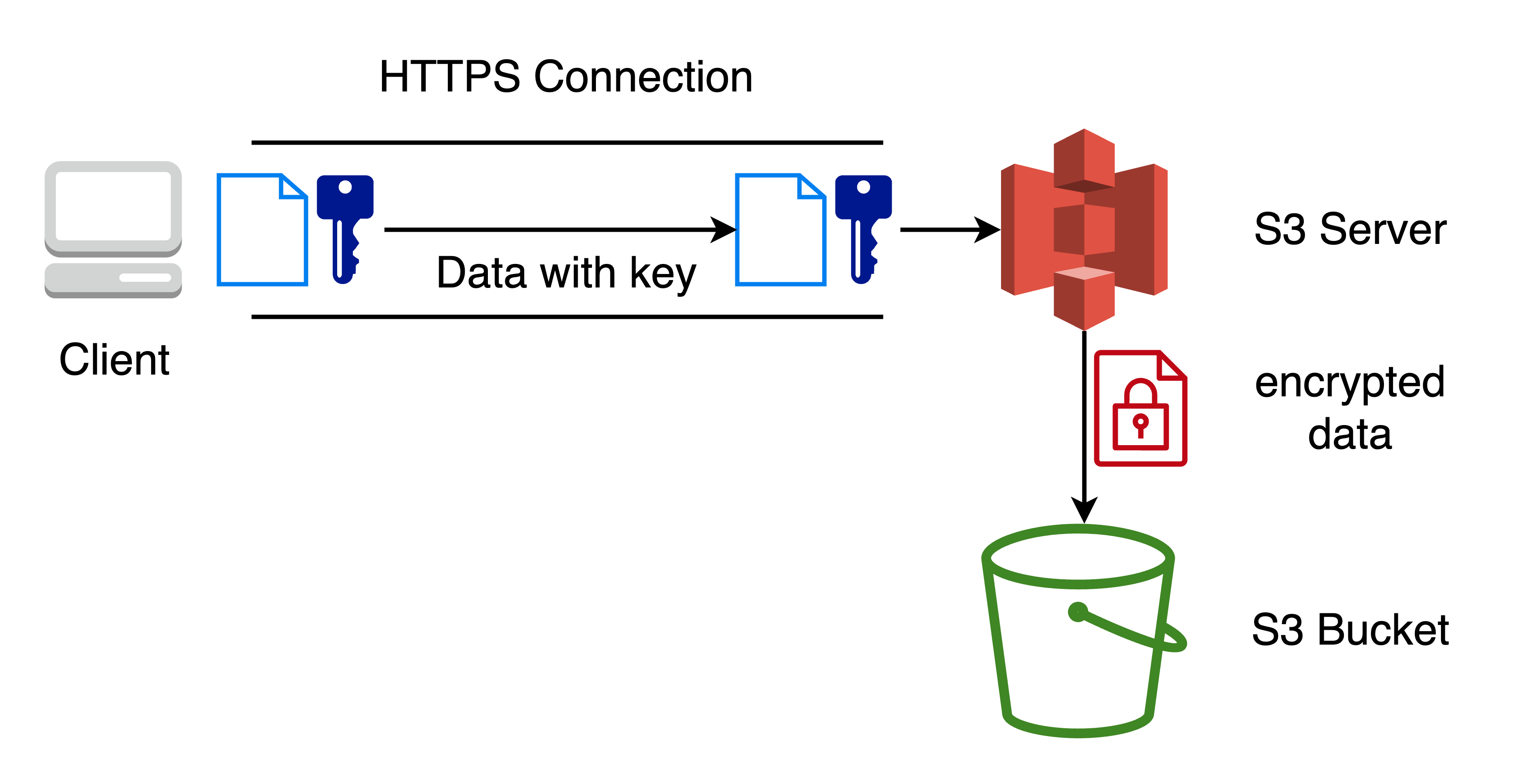
Server-side encryption with S3 managed keys (SSE-S3)
With SSE-S3, encryption at rest is achieved through encryption at the server with keys managed by S3. Every object has a unique key (Data Encryption Key) to encrypt and decrypt. With this method it uses 256-bit Advanced Encryption Standard (AES-256), to encrypt and decrypt the data. The Data Encryption Key is encrypted by the root/master key for an extra layer of security. SSE-S3 is the default encryption for the objects uploaded into the bucket.
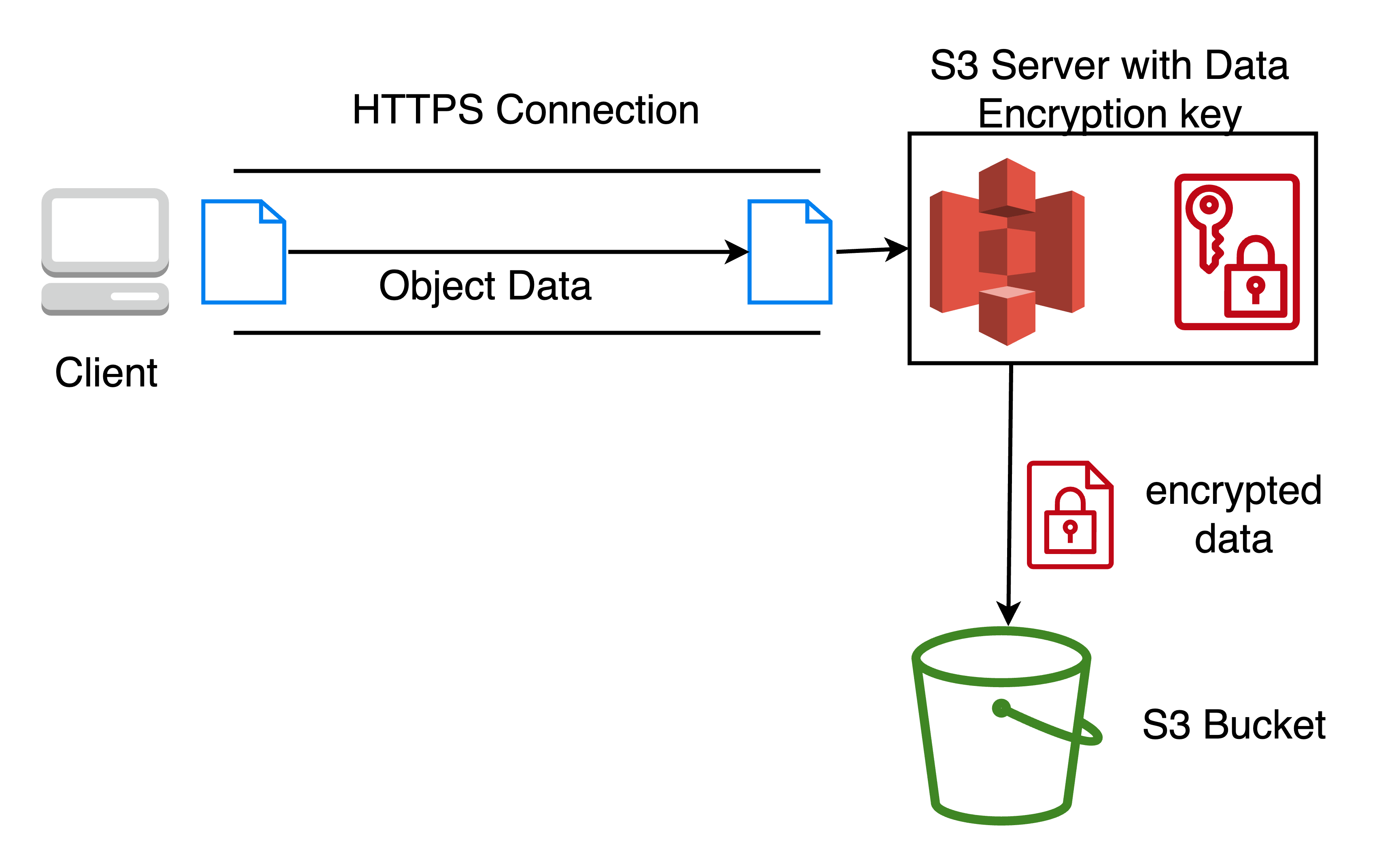
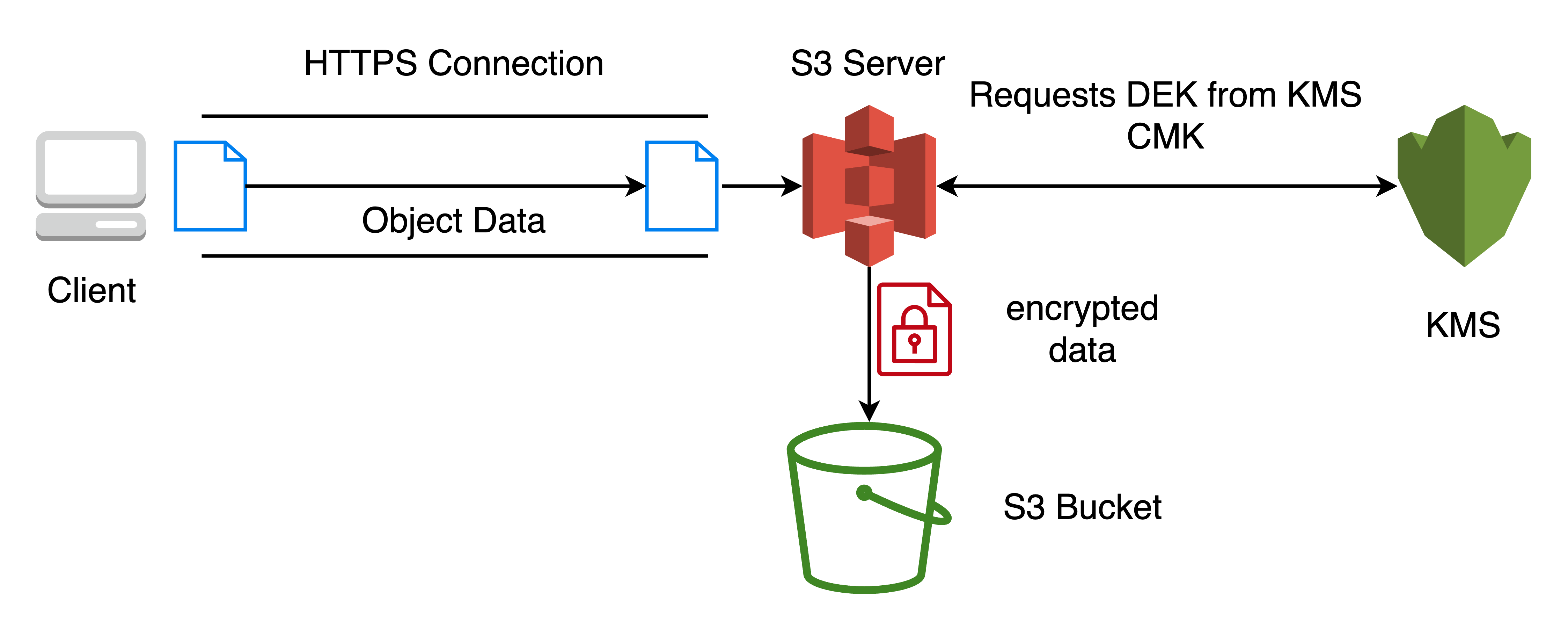
Server-side encryption with KMS (SSE-KMS)
With SSE-KMS, encryption at rest is achieved through encryption at the server with Customer Managed Keys from KMS. Every object has a unique key (Data Encryption Key) to encrypt and decrypt.
S3 Storage Classes
Amazon S3 has a variety of storage classes to choose from that can meet the needs of your workloads in terms of data access, resiliency, and cost. Storage classes are designed to offer the most cost-effective storage for different access patterns. Storage class can be understood as differentiating the data based on the access pattern to reduce the cost of storage. Different types of storage classes are
S3 Standard
S3 Intelligent-Tiering
S3 Standard-Infrequent Access
S3 One Zone-Infrequent Access
S3 Glacier Instant Retrieval
S3 Glacier Flexible Retrieval
S3 Glacier Deep Archive
S3 Standard
S3 Standard offers high durability, availability, and performance object storage for frequently accessed data. Objects in this storage class are replicated in at least 3 Availability Zones. There is no minimum size or minimum days for the objects in the storage class for billing.
S3 Intelligent-Tiering
S3 Intelligent Tiering is a storage class, which offers automation for storage cost reduction. This storage class can be used when we don't know the access pattern of the objects. This moves the data to different storage classes based on the access pattern it is observing. There will be an extra cost for monitoring the object's access patterns. Highly useful when we don't know the access pattern.
S3 Standard-Infrequent Access
S3 Standard-IA is for data that is accessed less frequently and requires quick access when needed. Objects in this storage class are replicated at least in 3 Availability Zones. S3 Standard-IA has a retrieval cost, when an object is requested then it is charged per GB retrieved. Also has a minimum size of 128 KB and 30 days minimum period for the objects in the storage class for the cost of S3 standard-IA to apply.
S3 One Zone-Infrequent Access
S3 One Zone-IA is for data that is accessed less frequently and requires quick access when needed. Objects in this storage class live only in 1 Availability Zones. S3 One Zone-IA has a retrieval cost, when an object is requested then it is charged per GB retrieved. Also has a minimum size of 128 KB and 30 days minimum period for the objects in the storage class for the cost of S3 One Zone-IA to apply.
S3 Glacier Instant Retrieval
The Amazon S3 Glacier storage classes are purpose-built for data archiving and are designed to provide you with the highest performance, and the lowest cost of archive storage in the cloud. Amazon S3 Glacier Instant Retrieval is an archive storage class that delivers the lowest-cost storage for long-lived data that is rarely accessed and requires retrieval in milliseconds. Amazon S3 Glacier Instant Retrieval has an expensive retrieval rate than the other archive solutions. Also has a minimum size of 128 KB and 90 days minimum period for the objects in the storage class for the cost of S3 Glacier Instant Retrieval to apply.
S3 Glacier Flexible Retrieval
S3 Glacier Flexible Retrieval delivers low-cost storage, up to 10% lower cost (than S3 Glacier Instant Retrieval), for archive data that is accessed 1 or 2 times per year. For archive data that does not require immediate access but needs the flexibility to retrieve large sets of data at no cost, such as backup or disaster recovery use cases. There are 3 types of retrieval,
Expedited (1 - 5 Mins)
Standard (3 - 5 Hours)
Bulk (5 - 12 Hours)
Also has a minimum size of 128 KB and 90 days minimum period for the objects in the storage class for the cost of S3 Glacier Flexible Retrieval to apply.
S3 Glacier Deep Archive
S3 Glacier Deep Archive is the lowest-cost storage class and supports long-term retention and digital preservation of data that may be accessed once or twice a year. Data retrieval can happen around 12 hours from the time it is requested. Also has a minimum size of 40 KB and 180 days minimum period for the objects in the storage class for the cost of S3 Glacier Deep Archive to apply.
S3 Lifecycle Configuration
S3 lifecycle is a set of rules defined in XML, that tells what to do when something happens to the bucket or group of objects. There are 2 types of actions
Transition Action - Moves the object from one storage class to another.
Expiration Action - Deletes the object from the bucket.
A transition action lifecycle rule may define, and move the object from S3 Standard to S3 Standard Infrequent Access after 60 days from the object creation on S3 Standard. Here you may have confused with S3 Intelligent Tiering and Lifecycle configuration, Intelligent Tiering continuously monitors the access pattern and cost is inclusive of that, whereas lifecycle configuration doesn't monitor regularly, those are a set of rules executed when conditions are met.
We cannot transition S3 One Zone IA to S3 Glacier Instant Retrieval through the lifecycle configuration.

S3 Bucket Replication
At a high level, S3 Bucket Replication is used to replicate the whole bucket or subset of the bucket objects to another S3 bucket. There are 2 types of replication,
Cross Region Replication
Same Region Replication
Replication is one way from the source to the destination bucket. Replication of objects will start from the point where the replication is enabled, the previous objects in the bucket are not replicated into the destination bucket. Versioning needs to be enabled for the bucket replication to work, when we suspend the versioning in one bucket, replication will be halted. By default, the destination bucket will use the same storage class as the source bucket, but we can able to change the storage class of the destination bucket. Lifecycle events on the source bucket are not replicated in the destination bucket.

S3 Presigned URL
Using the S3 Presigned URL, an AWS IAM user can able to give access to the object, to an unknown/unauthorized identity. With S3 Presigned URL, we can able to GET and PUT the objects into the buckets. We shouldn't create an S3 Presigned URL with IAM Roles, because temporary tokens may expire before the expiry of the Presigned URL, which makes the URL invalid. Always use the IAM user for generating the Pre signed URL.




